
https://arxiv.org/abs/2312.09505
Introduction
以下のようなものを提案した。
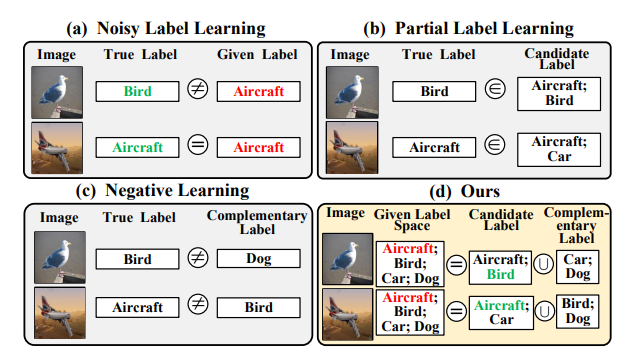
データに対して、Noisy Labelが与えられたとする。
それをCandidate LabelやComplementary Labelにうまく変換させる。
Related Works
- Noisy Labelについては省略。
- Partial Label Learningでは、「平均ベースの統計的知識を使う」、「明らかにわかるようなサンプルのラベルを明確にする」の2つである。
- 前者は学習の中で、すべてのラベル候補を同じ重みとして扱う。
- 後者は真のラベルという潜在変数を考え、各サンプルごとにあるConfidence Scoreというのを推定する。
- Negative Learning 補ラベルを用いた学習といえる。
Method
問題設定
- データは。
- 与えられるPartial Labelはである。
- 真のラベルはである。
- 目標は以下のようにsoftmax関数で訓練させた損失の最小化。
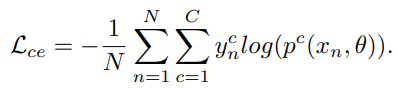
- 実装の際、one hotベクトルの要領で、Partial Label LearningとComplementary Label Learningはmulti-hotベクトルとして実装される。
確かに先行研究 📄![]() 2018-NIPS-[GCE]Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels などでは生のCross Entropyを使うと、Noisyなデータに弱いという事実があった。
2018-NIPS-[GCE]Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels などでは生のCross Entropyを使うと、Noisyなデータに弱いという事実があった。
この研究では、Cross Entropy Lossを使ったとしても、Partial Label LearningとNegative Learningを組み合わせることで、Cross Entropyでもいい性能が出るようにしたい。
ラベル空間の分解
Self-supervised Learningは誤ったPseudo Labelの付与による悪影響は避けられない。
なので、NoisyなラベルをうまくPartial LabelとComplementary Labelに分解したい。
与えられているNoisyなラベルについて、サンプルに対して最も正しそうな予測複数個を選び、これらはそれぞれone-hotラベルなので、以下のようにtwo-hotラベルになる。これをPartial Labelとして扱う。
そして、Complemental Labelを以下のように生成する。つまり、のbit反転。
このとき、Partial Labelには絶対に正しいのを含みたいが、Complementary Labelには正しいのを含ませたくない。この時、逆にPartial Labelは厳しく選びComplementary Labelは雑に選ぶという倒錯が起きる。
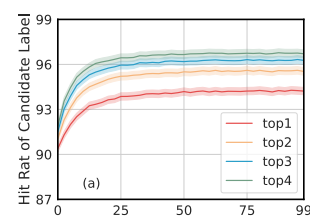
この手法の理論的な裏付けとして、Noisy Labelの予測のtop-kに正解が入っているかを見てみると結構入っている(top 2だけでも全然違う)
Partial Label Learningにおける曖昧性の解消
Partial Label Learningの手法として、ラベルの曖昧さを解消するというものがある。これを受けてこの論文では、hard曖昧性解消とsoft曖昧性解消の手法を考える。
を番目のデータについての、回目の学習時のラベル分布だとする。初期分布は与えられたNoisyかもしれないを使い、更新は今時点でのPartial Label(識別器の出力したラベル候補のtop-k)のを用いて更新する。
の中で最も大きい成分を持つものが最終的な識別器の予測結果になる。

はから考えられる正解ラベルであり、hard, softは以下のように定義される。
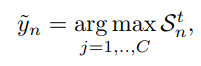
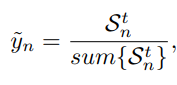
これに従い、Hard LabelとSoft Labelの損失も以下のように定義する。基本的にをreweightingしながらのクロスエントロピー損失である。
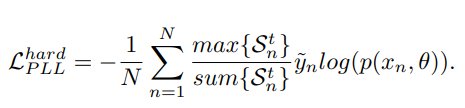
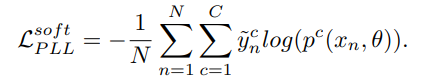
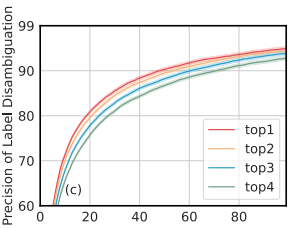
Partial Labelは多ければよいわけではない
候補が多いほど、当然disambiguationの精度が下がってしまう。
Negative Learningの導入
さきほどののように計算されるのがComplementary Label。これについて、以下のような式でComplementary Labelに入っているものの確率を下げる。
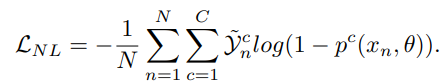
全体の枠組み
全体としては以下のObjectiveで訓練する。
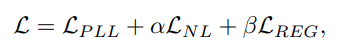
正則化項は予測の一貫性を持たせるもので、弱いデータ拡張と強いデータ拡張をしたものの予測によるCross Entropy損失低い=違うデータ拡張しても同じように予測されることが望ましい。
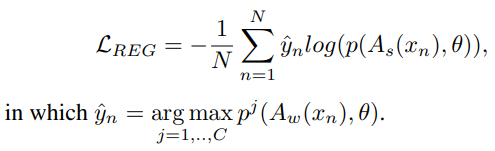
全体のアルゴリズム
- ウォームアップしている。
- Noisy Labelのまま学習する。
- ウォームアップが終わったら。
- 識別器の予測top-kのもので、Partial Labelを生成。
- そのPartial Labelに基づくComplementary Labelを生成。
- 今のエポックのラベル分布を更新。
- 損失を計算する。
考察
Complemental LabelはNegative Loss。📄![]() 2023-NIPS-Active Negative Loss Functions for Learning with Noisy Labels 。この論文と似ていて面白い。
2023-NIPS-Active Negative Loss Functions for Learning with Noisy Labels 。この論文と似ていて面白い。
どちらもActive LossとNegative Lossを同時に利用していることでノイズに強いことを実現。
実験
- CIFAR100Nを使用。ノイズは対称ノイズ、非対称ノイズを使う。
- Real Noisy Dataとして、Web-Aircraft, Web-Car, WebBirdを使用。
NPN-hardのほうが大体よかった。
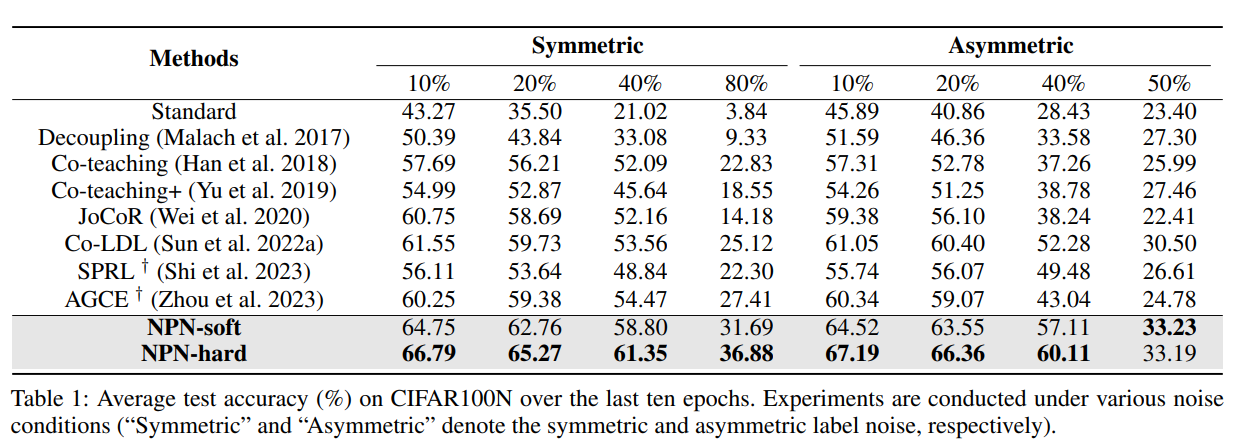
あとAblation Studyでは、Negative Label Learningは強力だった。